¶ Prerequisites
¶ Minimal system requirements
Currently (as of March 2023) a working node consumes about 3 GB RAM and close to no CPU (<1%), so any decent hardware setup will do (as long as the CPU is 64-bit). But when syncing, and sometimes when a DAG structure becomes more intricate, its RAM consumption grows to at least 8 GB. Also the CPU power significantly affects initial synchronization time. So it's recommended to have a 8 GB free RAM (and it is requires for syncing from scratch) and a couple of free CPU cores to run a node.
Under normal circumstances a freshly synced node takes about 4 GB of disc space, but this may be larger depending on the DAG structure, sometimes up to 20 GB and even 45GB (it's a really rare case). And this space grows for approx. 1 GB each day, so make sure you have enough free space on your SSD/HDD. Storage volume speed is not significant since Kaspa's data flow is slow enough (order of tens kb/s). And the you can anytime resync the node from scratch to reset the used disk space back to ~4 GB.
¶ Download a proper version of Kaspa core files archive
Download the ZIP archive of precompiled files of the latest release from the official repository. Choose a proper version for your OS: xxx-win64.zip for Windows users, xxx-osx.zip for Mac user, xxx-linux.zip for Linux. Make sure you're not downloading the testnet release (the one with the "Testnet" postfix in the release name), these are for a developers' test network, not the main one you need.
¶ Setting up a node in Windows
¶ Unzip the downloaded archive
Extract the downloaded archive to whatever location suitable for you.
In the following text, all examples will be written for the case when files are unpacked into a C:\Kaspa\ folder. If you unzip the archive to another folder, replace this path in the examples and explanations with your own. Also, all explanations are given for Microsoft Windows.
After unpacking, there will be 5 files in the C:\Kaspa\ folder: genkeypair.exe, kaspactl.exe, kaspad.exe, kaspaminer.exe and kaspawallet.exe, the one you need is a kaspad.exe. Later you will also need a kaspawallet.exe for creating a wallet, see the according article. Don't use kaspaminer.exe: it is a reference miner implementation, there are much more efficient ones, see Mining.
¶ Create a batch file
You can run kaspad.exe right here and now, but since it can sometimes crash, it's better to put it in an endless loop by creating a windows batch execution (.bat) file. To create it, right click in the C:\Kaspa\ folder window, select "Create->New text document" and then rename the created file into, say, kaspad.bat. Make sure Windows doesn't hide file extensions from you, otherwise you'll end up with a file named kaspad.bat.txt without knowing it, and that's not what you need.
Open this file with a Windows Notepad, and add the following lines into it:
:xxx
kaspad.exe --utxoindex
goto xxx
This way when a node crashes it will restart automatically. From now on, you may start a node anytime by double-clicking that kaspad.bat file. Although you should read further before doing it.
The --utxoindex flag makes kaspad calculate per-address balances and cache them for further usage with wallet operations. If you don't need to check balance and send coins, but only mine to the node, you can omit this parameter.
¶ Default folders
Kaspad keeps its data (a DAG database, log files, config files, memory dumps) in the %localappdata%\Kaspad folder. After the initial syncing process this folder will have a size of about 3 GB, and in about a month it will grow to 30 GB.
If you're OK with this, do nothing.
If you want this data to be stored in another location (say, you have a limited storage space on a system disc), use an --appdir (or -b that is the same) command line parameter along with the others. For example, if you want the data to be stored in the c:\kaspa_data folder, your command line should look like kaspad.exe --appdir c:\kaspa_data --utxoindex. Kaspad does not require fast HDD/SSD for now, so you may easily set its files to be stored on a large-volumed low-speed HDD.
¶ Bootstrap database snapshot
Nowadays using the DB bootstrap is almost never justified since the process of syncing from scratch usually takes about 30 minutes. But if you still feel it will end sooner with the bootstrap (in case you have a really old PC, less than 8 GB of RAM or a very slow internet connection), you can download an archive of a kaspad's database either from a http://www.kaspadbase.com/ (both Windows and Linux version archives could be used in any OS, because kaspad's files structure is cross-platform), of find a newest archive in the #datadir_exchange channel of the Kaspa Discord server.
Unzip the archive so that its kaspa-mainnet folder gets into the %localappdata%\Kaspad folder of your PC, or whatever folder you've chosen on the previous step. If you have never started kaspad before and never created said folder, you'll have to manually create it first.
If there's already a kaspa-mainnet folder in the destination folder, it's highly recommended to delete it before, so to avoid files mess from the different kaspad starts. Kaspad DB engine won't like that mess for sure, and may crash.
¶ Set special parameters
If you know some working node's IP in your LAN and want to make a hint for kaspad about using that node as a data source, use the --addpeer <other node's IP address> command line parameter along with the others.
If you want some node to be your kaspad's only source of data, use a --connect <other node's IP address> command line parameter.
You can see a whole set of other available parameters along with their descriptions and, sometimes, default values, by running kaspad with the --help command line parameter. To see a more detailed help about certain command, you may run kaspad <that command> --help.
¶ Start
Double-click your kaspad.bat file. Don't run it as the administrator, there's a chance of failure in that case because of implicit working directory change. Run it as a usual user.
You'll see a console (text) window with the kaspad's execution log.
¶ Synchronization stages
The syncing process normally consists of 2 short and 3 large synchronization stages: processing pruning point proof (a short one), processing headers, fetching the pruning point UTXO set (another short one), processing blocks, and building a DAG. This is for syncing completely from scratch; it you're using a DB snapshot there may be less stages depending on the state of snapshot data in comparison to actual DAG state.
To get familiar with the log content in general, have a look at section Log content explanation.
¶ Processing pruning point proof
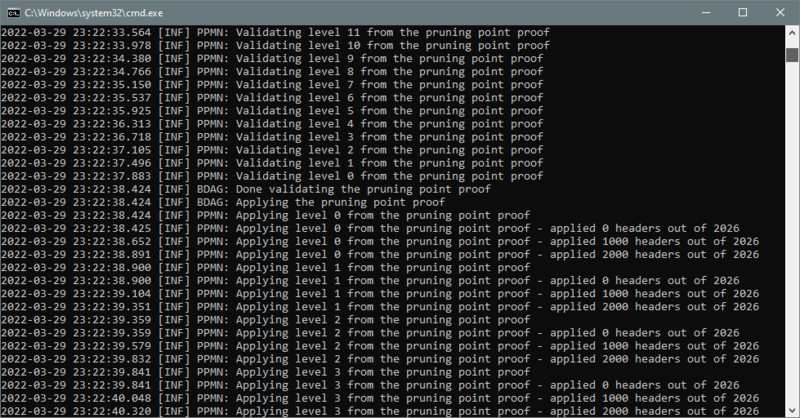
Pruning point proof processing comprises proof's downloading, validating and applying substages. It normally takes less than a couple of minutes.
¶ Processing headers
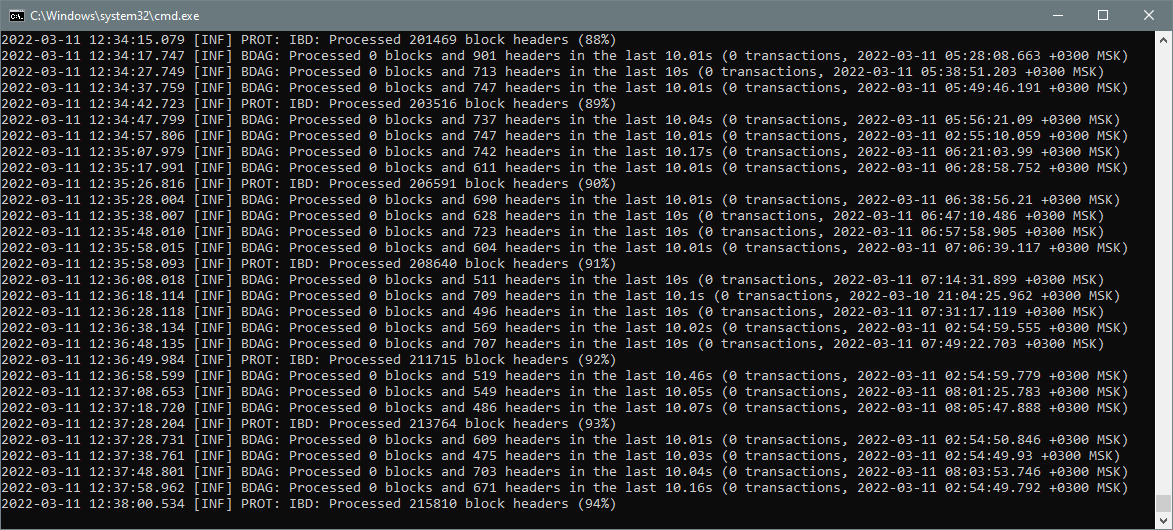
After a pruning point proof processing is completed, there will start a relatively long stage of processing headers. You will see that block headers are processed from 3 days ago to the current time. The time of headers being currently processed (i.e. when these headers' appropriate blocks were created) could be seen in the last part of each "Processed 0 blocks and X headers" line. You will also see a line "[INF] PROT: IBD: Processed XXX block headers (N%)" for each next percent of a total stage completion.
This stage is the longest one and usually takes 20 minutes to 2 hours depending on the DAG's structure in the previous 3 days, and on your storage device speed characteristics.
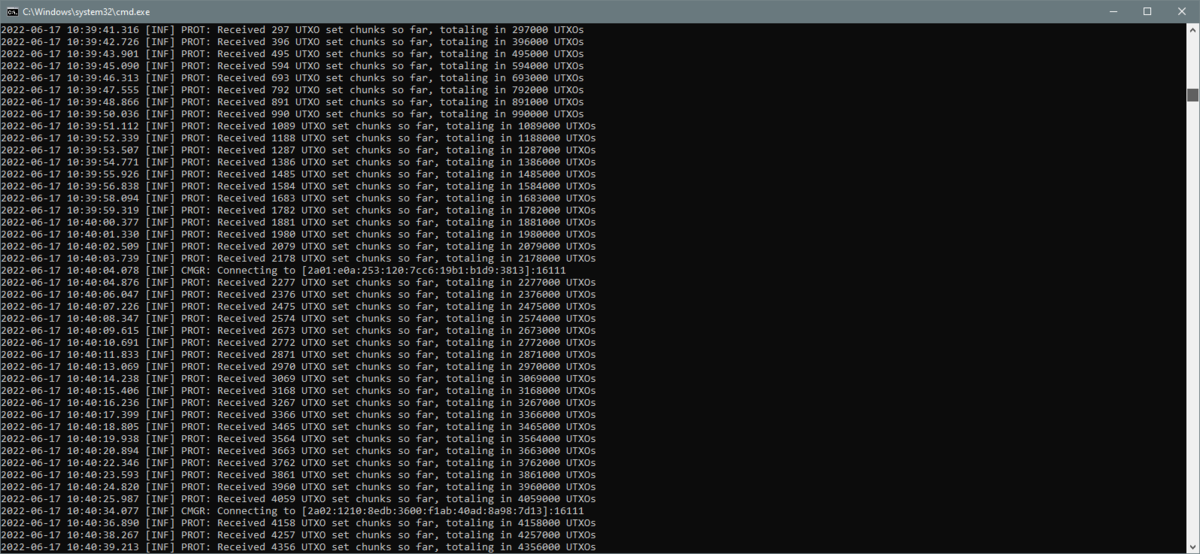
¶ Fetching the pruning point UTXOs
Having headers processed, the node gathers the set of UTXOs that corresponds to a pruning point. This stage is indicated by "[INF] PROT: Received XXX UTXO set chunks so far, totaling in YYY UTXOs" lines and takes about a couple of minutes, ending with the string "[INF] PROT: Finished receiving the UTXO set. Total UTXOs: ZZZ".
This stage takes about a minute.
¶ Processing blocks
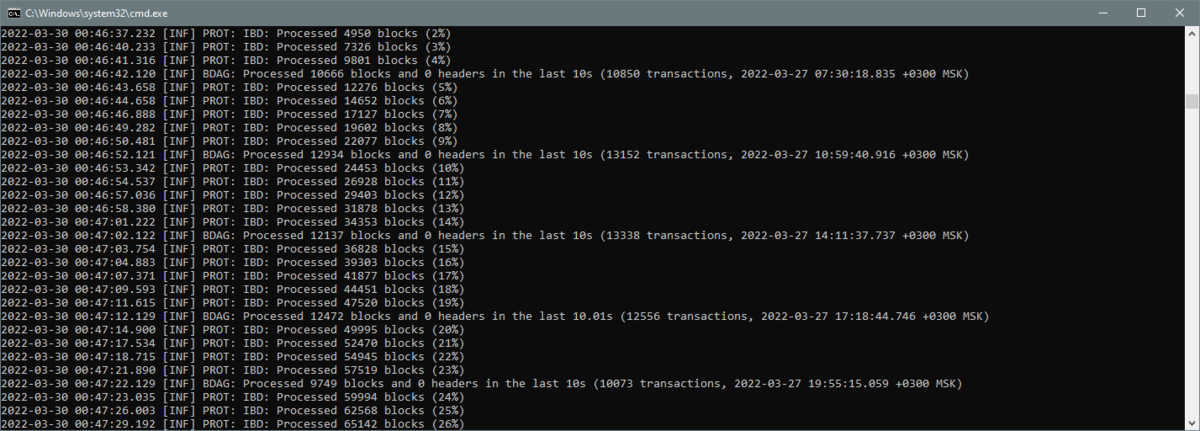
After the UTXO set is fetched there will start another longer stage of processing appropriate block bodies corresponding to previously received block headers. You will now see that block are processed from the same 3 days ago to the current time. The time of blocks being currently processed (i.e. when these blocks were created) could be seen in the last part of each "Processed X blocks and 0 headers" line.
This stage usually takes 5 to 20 minutes.
¶ Resolving virtuals
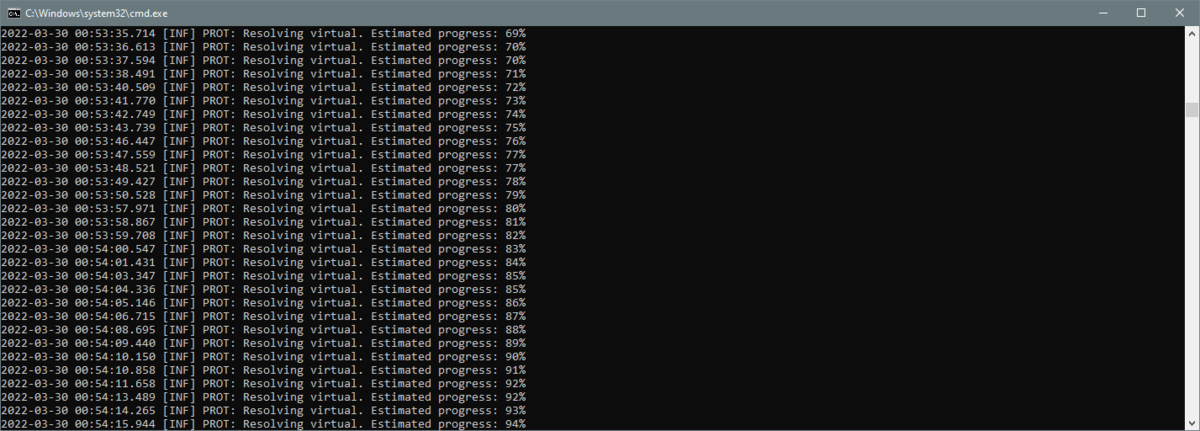
This stage is the last one and a short one too and takes only several minutes at the longest. You'll see multiple "[INF] PROT: Resolving virtual. Estimated progress: XX%" lines.
¶ Possible new round
As the syncing process takes significant time, but DAG keeps building further all that time, then by the end of the syncing process another bunch of data will become ready that must be processed in order for the node to become fully synchronized. So the last 3 stages will happen again but much faster this time, since it's only required to process these 20 minutes to 2 hours worth of data that the syncing process have taken. And then maybe once again, depending on the CPU power and RAM size of your PC.
¶ Node is synced
When you'll see a stream of messages "[INF] PROT: Accepted block XXX via relay" in the node's window output, this will mean the node is fully synced.
¶ Normal operation
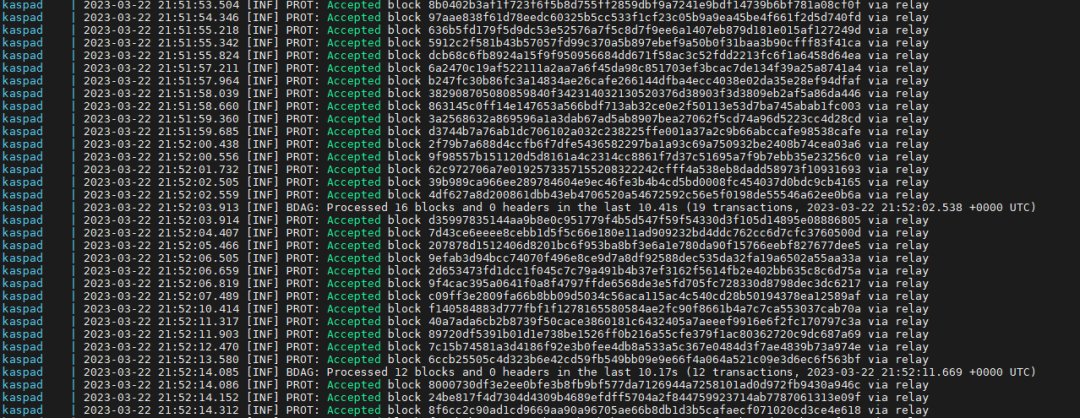
Usually most of node's output consists of lines "Accepted block XXX via relay", but every now and then you'll see lines like "Ignoring duplicate block XXX", "Received a block with missing parents, adding to orphan pool: XXX", "Unorphaned block XXX", "Block XXX has X missing ancestors. Adding them to the invs queue" and even again "IDB", "Resolving virtual" and "IDB finished successfully". This all is a normal way of node's operation and is based on the DAG's distributed nature where data sometimes comes in unexpected order yet the node must take care of it.
¶ Setting up a node in HiveOS
There's a nice sample one-liner from a Discord user @supertypo:
wget https://github.com/kaspanet/kaspad/releases/download/v0.12.2/kaspad-v0.12.2-linux.zip -O /tmp/kaspad.zip ; unzip -j /tmp/kaspad.zip bin/kaspad; ./kaspad --utxoindex
Just make sure to visit Kaspa's github releases page to know what's the current latest release, and replace the v0.12.2/kaspad-v0.12.2-linux.zip sub-string in this one-liner with the appropriate path to a zip-file of the latest release version for Linux.
All the other parts of a node installation process is similar to Windows's one, so refer to the previous chapter to see the details.
¶ Setting up a node on Linux
To setup kaspad as a systemd service on Linux, see the following steps.
¶ Install binaries
- Download Linux archive from Github release area e. g. like this:
$ wget https://github.com/kaspanet/kaspad/releases/download/v0.12.14/kaspad-v0.12.14-linux.zipThe ready to use binaries are currently available only for x86_64 architecture, so if you on a different architecture (like Raspberry Pi), you need to compile yourself.
- Unzip archive onto
/usr/local/:
$ sudo unzip ~/kaspad-v0.12.14-linux.zip -d /usr/localAs the downloaded archive already contains a subfolder bin/, all the binaries will be located below /usr/local/bin/ afterwards, so they can be used right from the cmdline.
$ kaspad --version
kaspad version 0.12.14
¶ Setup systemd service
- Create the file
/etc/systemd/system/kaspad.servicewith the following content:
[Unit]
Description=Kaspad Service
After=network.service
[Service]
User=hlxeasy
WorkingDirectory=/home/hlxeasy
ExecStart=/usr/local/bin/kaspad --utxoindex
# optional items below
Restart=always
RestartSec=3
[Install]
WantedBy=multi-user.target
Replace all occurrences of hlxeasy with your used account name
- Reload systemd
$ sudo systemctl daemon-reload¶ Check and start service
$ sudo systemctl status kaspad.service
* kaspad.service - Kaspad Service
Loaded: loaded (/etc/systemd/system/kaspad.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Sep 29 20:08:01 coruscant2 kaspad[2020]: 2023-09-29 20:08:01.416 [INF] KASD: Received signal (terminated). Shutting down...
Sep 29 20:08:01 coruscant2 kaspad[2020]: 2023-09-29 20:08:01.416 [INF] KASD: Gracefully shutting down kaspad...
Sep 29 20:08:01 coruscant2 kaspad[2020]: 2023-09-29 20:08:01.417 [WRN] KASD: Kaspad shutting down
Sep 29 20:08:01 coruscant2 kaspad[2020]: 2023-09-29 20:08:01.418 [INF] KASD: Kaspad shutdown complete
Sep 29 20:08:01 coruscant2 kaspad[2020]: 2023-09-29 20:08:01.418 [INF] KASD: Gracefully shutting down the database...
Sep 29 20:08:01 coruscant2 systemd[1]: Stopping Kaspad Service...
Sep 29 20:08:01 coruscant2 kaspad[2020]: 2023-09-29 20:08:01.424 [INF] KASD: Shutdown complete
Sep 29 20:08:01 coruscant2 systemd[1]: kaspad.service: Succeeded.
Sep 29 20:08:01 coruscant2 systemd[1]: Stopped Kaspad Service.
Sep 29 20:08:01 coruscant2 systemd[1]: kaspad.service: Consumed 29.907s CPU time.
$ sudo systemctl start kaspad.service
To see the service logs, journalctl is the tool of choice:
$ sudo journalctl -u kaspad -n 1000 -f¶ Enable service for autostart
If all runs smooth, the service should be enabled for automatic startup
$ sudo systemctl enable kaspad.service
Created symlink /etc/systemd/system/multi-user.target.wants/kaspad.service -> /etc/systemd/system/kaspad.service.
¶ Setting up a node in Docker
¶ Using ready-made container image
The image is built for Linux x86-64.
Docker must be installed.
For quick start with docker, an already made image could be used:
docker run --pull always -d --restart unless-stopped -p 16110:16110 -p 16111:16111 --name kaspad supertypo/kaspad:latest
More information about running kaspad in docker, including peristent storage, multiple instances and load balancing: https://hub.docker.com/r/supertypo/kaspad
¶ Build image from source
To build the node from source the following Dockerfile could be used:
FROM golang:1.18.2 as builder
RUN mkdir /app
WORKDIR /app
#RUN git clone --depth 1 --branch v0.12.1-rc7 https://github.com/michaelsutton/kaspad
RUN git clone https://github.com/kaspanet/kaspad
WORKDIR /app/kaspad
RUN go install -ldflags '-linkmode external -w -extldflags "-static"' . ./cmd/...
FROM alpine:latest
COPY --from=builder /go/bin /
EXPOSE 16110
EXPOSE 16111
EXPOSE 8082
CMD sh
If you want to build a test version, please find the commented line where you can set branch/tag you would like to download and build.
To build the node image, type:
docker build -t kaspa .
¶ Run node in container
To run the kaspa image in docker, a docker-compose.yml file could be created as below:
version: '3.5'
services:
kaspad:
image: kaspa
container_name: kaspad
restart: always
volumes:
- ./datadir2:/root/.kaspad/kaspa-mainnet/datadir2
ports:
- "16110:16110"
- "16111:16111"
- "8082:8082"
command: '/kaspad --utxoindex'
Then run the container with command:
docker-compose up -d
¶ Making your node accessible for incoming connections
If you plan to make a miner and a wallet work with your node on the same PC where the node is started, you shell do nothing — node's completely available on a local host for both of them.
But if you want to have access to your node from another PC in the same LAN (say in order to make a separate mining rig work with that node, or to be able to check balance and send coins from a laptop inside your home LAN), then make sure you've set up your firewall to allow connection to port 16110 for a kaspad.exe process on the PC where the node (or KDX if you use its node) is running. This port belongs to so called RPC protocol, the one which is used by both miner and wallet to communicate to a node. If you also want other nodes in your LAN to be able to actively connect to your node, you should allow connections to port 16111 which is used for inter-nodes communication (for both initial synchronization and further data exchange).
Both these port numbers are default and could be changed via --rpclisten localhost:<RPC port number> and --listen localhost:<node-to-node protocol port number> respectively. It that case don't forget to also explicitly define your non-default ports when setting up command-line parameters for a wallet daemon and a miner.
If you also want the functions mentioned to be available when connecting to your node from Internet, make sure you've forwarded these ports in your router (see its manual to know how to do it). And call your ISP to know if you're not behind its NAT, or maybe that you should otherwise purchase a "static white IP" service to guarantee that your router (and thus your node) have an Internet-wise IP address that will not change over time (or with each router restart, or whenever you ISP would like it to have changed).
Port forwarding is not required if you only want your node to see other nodes: it will still be able to connect to other, public nodes, that have their port 16111 open. Port forwarding only allows other nodes to actively connect to your node, thus making your node "public". On the other hand, making your node public (forwarding port 16111) increases Kaspa network connectivity and in general is good for it. Take into account that forwarding port 16110 (RPC one) allows everyone to connect to your node so to mine to it, check their balance on your node, etc.
¶ Troubleshooting
If something goes wrong, it is recommended to add a pause command before the goto xxx line of your kaspad.bat file to see the node's output, so that kaspad.bat file's content look like:
:xxx
kaspad.exe --utxoindex
pause
goto xxx
This way you can make a screenshot or copy the node's output text to ask for help in the Discord's #help-node channel. But prior to do that make sure you've read and done the following: usually when the node crashes, it then restarts successfully right away (if you're using a .bat file) then keeps working. If it's not, then you should first get to the %localappdata%\Kaspad\kaspa-mainnet\datadir2 folder and delete several newest files in it and try to run a node once again, maybe repeat this several times. If it does not help then delete all files there and resync from scratch according to this article (in order to make kaspad delete all DB files for you you can also use an additional --reset-db command line parameter, but don't forget to remove this parameter later, otherwise you'll end up syncing from scratch every time node is restarted). If even that still does not help, go to Discord to ask for volunteers' support.